Как конвертировать CHM в один PDF на Linux: без мусора и битых ссылок
Пошагово: распаковать CHM в HTML, почистить ссылки и собрать один PDF через wkhtmltopdf. Диагностика, типовые ошибки, проверка результата.
Требования
- Linux (Ubuntu/Debian предпочтительно)
- Доступ к консоли (ssh/локально)
- Утилиты: extract_chmLib + wkhtmltopdf
Как конвертировать CHM в один PDF на Linux: без мусора и битых ссылок
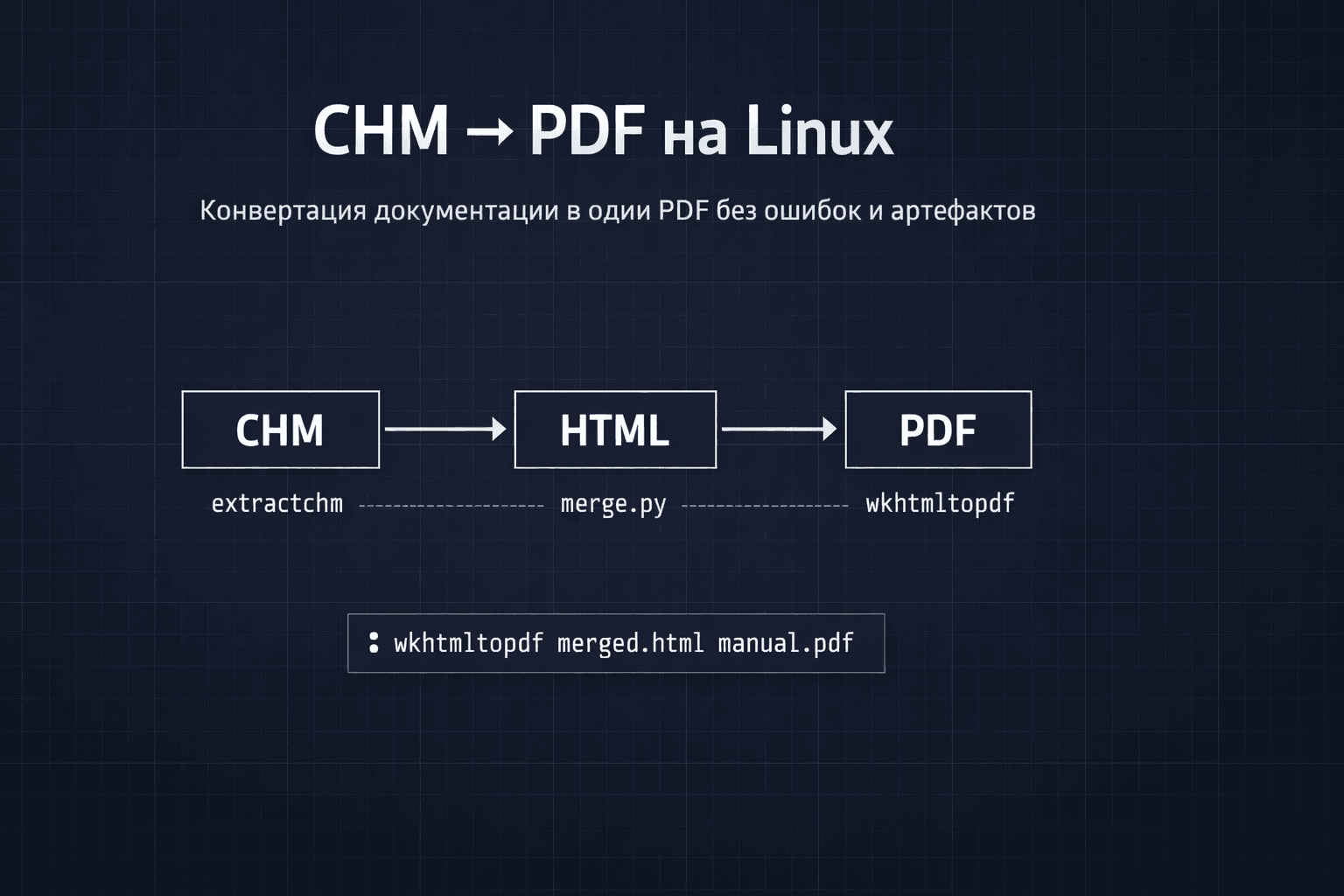
Если у тебя есть bsm_api.chm и нужно получить один нормальный PDF, а не «папку из 900 HTML + слёзы», вот рабочий пайплайн: CHM → HTML → (сборка) → PDF.
В конце будет:
- один
manual.pdf - без битых внутренних ссылок (насколько позволяет исходник)
- с нормальной навигацией/оглавлением (если CHM адекватный)
В чём проблема
CHM — это не “один файл с текстом”, а контейнер: HTML + картинки + оглавление + внутренние ссылки.
Типовые боли:
- конвертеры делают 1000 страниц вместо одного PDF
- ломают ссылки и кодировки
- получаешь PDF, который выглядит как скриншоты из 2007
Рабочее решение
1) Установка инструментов
Ubuntu/Debian:
sudo apt update
sudo apt install -y \
extractchm \
wkhtmltopdf \
python3 \
python3-bs4 \
python3-lxmlЕсли extractchm нет (редко, но бывает), ставим из chmlib:
sudo apt install -y chmlib-tools
# потом будет утилита extract_chmLibПроверка:
extractchm -h || true
wkhtmltopdf --version2) Распаковать CHM в HTML
Создай рабочую папку:
mkdir -p ~/work/chm2pdf/{src,html,out}
cp bsm_api.chm ~/work/chm2pdf/src/
cd ~/work/chm2pdfРаспаковка:
Вариант A (extractchm):
extractchm -o html src/bsm_api.chmВариант B (extract_chmLib):
extract_chmLib src/bsm_api.chm htmlПроверка что распаковалось:
ls -la html | head
find html -maxdepth 2 -type f | head3) Найти “точку входа” (главную страницу)
Обычно это index.html, default.html, start.html или что-то из оглавления.
Быстрый поиск кандидатов:
ls html | grep -iE 'index|default|start|main' || trueЕсли не очевидно — ищем самый “толстый” HTML:
find html -type f -iname '*.html' -printf '%s\t%p\n' | sort -n | tail -204) Собрать единый HTML (важный шаг)
wkhtmltopdf лучше работает, когда ты отдаёшь ему одну HTML-страницу, а не тысячу.
Сделаем “склейку”: берём список страниц и собираем в out/merged.html.
Вот минимальный Python-скрипт, который:
- читает оглавление (если найдём файл типа
.hhc/toc) - если оглавления нет — склеивает HTML по алфавиту (хуже, но работает)
- вырезает мусорные
script/iframe - приводит относительные ссылки к локальным путям
Создай файл tools/merge.py:
#!/usr/bin/env python3
import os
import re
from pathlib import Path
from bs4 import BeautifulSoup
ROOT = Path("html").resolve()
OUT = Path("out")
OUT.mkdir(parents=True, exist_ok=True)
def list_html_files():
# 1) Если есть оглавление — можно допилить парсер под конкретный CHM
# 2) Универсальный fallback — склеим HTML по имени
files = sorted(ROOT.rglob("*.html"))
# выкинем дубли/служебное
files = [p for p in files if p.is_file() and p.stat().st_size > 200]
return files
def clean_body(html_path: Path) -> str:
data = html_path.read_bytes()
# грубая попытка с кодировкой
for enc in ("utf-8", "cp1251", "windows-1251", "latin-1"):
try:
text = data.decode(enc)
break
except UnicodeDecodeError:
continue
else:
text = data.decode("utf-8", "ignore")
soup = BeautifulSoup(text, "lxml")
# выкидываем потенциальный мусор
for tag in soup(["script", "iframe", "noscript"]):
tag.decompose()
body = soup.body or soup
# нормализуем якоря и локальные ресурсы
for a in body.find_all("a", href=True):
href = a["href"].strip()
# убираем внешние и mailto
if href.startswith(("http://", "https://", "mailto:")):
continue
# normalize windows slashes
a["href"] = href.replace("\\", "/")
# добавим заголовок-разделитель
title = soup.title.get_text(strip=True) if soup.title else html_path.name
header = f"<h1>{title}</h1>\n"
return header + str(body)
def main():
parts = []
for p in list_html_files():
try:
parts.append(clean_body(p))
except Exception as e:
print(f"skip {p}: {e}")
merged = f"""<!doctype html>
<html>
<head>
<meta charset="utf-8" />
<title>CHM merged</title>
<style>
body {{ font-family: Arial, sans-serif; line-height: 1.45; }}
pre, code {{ white-space: pre-wrap; word-wrap: break-word; }}
h1 {{ page-break-before: always; }}
</style>
</head>
<body>
{''.join(parts)}
</body>
</html>
"""
(OUT / "merged.html").write_text(merged, encoding="utf-8")
print("OK -> out/merged.html")
if __name__ == "__main__":
main()Запуск:
mkdir -p tools out
python3 tools/merge.py
ls -la out/merged.html5) Конвертировать merged.html → PDF
wkhtmltopdf \
--enable-local-file-access \
--encoding utf-8 \
--page-size A4 \
--margin-top 12 --margin-bottom 12 --margin-left 10 --margin-right 10 \
out/merged.html out/manual.pdfПроверка результата:
ls -lah out/manual.pdf
file out/manual.pdfПроверка результата
Минимум:
- PDF открывается, вес адекватный (не 2 KB и не 2 GB)
- есть текст (не “картинки страниц”)
- код/таблицы читаются
Быстрый sanity-check: извлечь пару строк текста:
python3 - <<'PY'
import subprocess, sys
p = subprocess.run(["pdftotext", "out/manual.pdf", "-"], capture_output=True, text=True)
print(p.stdout[:800])
PYЕсли pdftotext нет:
sudo apt install -y poppler-utilsТипичные ошибки
❌ 1) “Blocked access to file” / не видит картинки
Причина: wkhtmltopdf по умолчанию режет локальные ресурсы.
Решение: добавь --enable-local-file-access (в примере уже есть).
❌ 2) Кракозябры вместо русского
Причина: HTML в CP1251, а ты склеил как UTF-8. Решение:
- в
merge.pyмы пробуемcp1251/windows-1251 - если всё равно плохо — найди реальную кодировку исходников:
file -i html/*.html | head❌ 3) “Оглавление” нет, порядок глав сломан
Причина: CHM хранит структуру в .hhc/.hhk, а мы склеили “по алфавиту”.
Решение: дописать парсер оглавления под конкретный CHM (реально 20–40 строк, если структура нормальная).
Если хочешь — кидай список файлов из html/ (без содержимого), я подскажу точечно.
Где применять
- Локально: быстро получить PDF, отдать в LLM/коллегам/заказчику.
- CI/CD: автогенерация документации в PDF (если CHM как артефакт).
- VPS: можно крутить без GUI, чисто консолью.
Смотри также
Если будешь ковыряться с файлами и поиском по дереву — пригодится:
- Поиск файлов в Linux: команды для Ubuntu/CentOS — диагностика и find
- find: поиск больших файлов — когда PDF внезапно 900MB
- rsync: безопасное копирование с прогрессом — перенос распакованного CHM или готового PDF
Похожие статьи


Комментарии